Learn how to setup an EJBCA PKI using Systemd quadlets.
With a fellow system administrators, I have spent in 2025 quite some thought on a nice PKI setup with EJBCA (community edition). Personally, I do not like EJBCA too much. It feels like an old monolithic java application with a slightly refreshed web GUI that consumes way too much resources for what it does. On top, the company backing EJBCA has not published the build scripts for their Docker container. Previously, Bitnami had an opensource build of EJBCA, but due to the Bitnami policy changes, this option is gone. I find the configuration of the EJBCA docker container is not well documented. Nevertheless, it is convenient for organisations that require some GUI for end-users to extend their certificates.
In the following, I just paste some of our configuration files to inspire others.
This post concerns the requirements of a Linux distribution for Europe in the context of the EU OS project and offers a comparison of Linux distributions.
Please note that views expressed in this post (and this blog in general) are only my own and not of my employer.
Update as of 31st May 2026: Please check out also the recording with my slides of my fosdem 2026 talk on the same topic.
Soon, the EU OS project celebrates its first anniversary. I want to seize the occasion (and your attention) before the Christmas holidays to share my personal view on the choice of the Linux distribution as a basis for EU OS. EU OS is so far a community-led initiative to offer a template solution for Linux on the Desktop deployments in corporate settings, specifically in the public sector.
Only few weeks ago, the EU OS collaborators tested together a fully functional Proof of Concept (PoC) with automatic provisioning of laptops and central user management. The documentation of this setup is to 90% complete and should be finalized in the coming weeks. This PoC relies on Fedora, which is the one aspect that triggered the most attention and criticism so far.
I recall that EU OS has so far no funding and only few contributors. Please check out the project Gitlab, join the Matrix channel, or send me an email to help or discuss funding. So in my view, EU OS can currently accomplish its mission best by bringing communities and organisations together to use their existing resources more strategically than now.
In 2025, digital sovereignty was much discussed in Europe. I had many opportunities to discuss EU OS with IT experts in the public sector. I am hopeful that eventually one or several European projects will emerge to bring Linux on the (public sector) Desktop more systematically as it is currently the case.
I also learnt more about public sector requirements for Linux on the server, in the VM, in Kubernetes. If the goal of EU OS is to leverage synergies with Cloud Native Computing technologies, those requirements must be considered as well by the Linux distribution powering EU OS.
Linux Use in the Public Sector
Let us map out briefly the obvious use cases of Linux in a public sector organisation, such as a ministry, a court, or the administration of a city/region. The focus is on uses that are directly managed1.
Linux on the desktop (rarely the case today, but that’s the ambition of the EU OS project)
Linux in a Virtual Machine (VM), a Docker/Podman Container, and for EU OS in a Flatpak Runtime
Linux on the server (including for Virtualisation/Kubernetes nodes)
Criteria for a Linux Distribution in the Public Sector
Given the exchanges I had so far, I would propose the following high-level criteria for the selection of a Linux Distribution:
Battle-tested Robustness
The public sector is very conservative and any change to the status-quo requires clear unique benefits.
Cloud Native Technology
The public sector reacted so far very positively to the promises of bootc technology (bootc in the EU OS FAQ). It is very recent technology, but the benefits for the management of Linux laptop fleets with teams knowing already container technology are recognised.
Enterprise Support
The public sector wants commercial support for a free Linux with an easy upgrade path to a managed enterprise Linux. Already existing companies, new companies, the public sector, or non-profit foundations could deliver such enterprise Linux. I expect that a mix with clear task allocations would work best in practice.
Enterprise Tools
The public sector needs tools for provisioning, configuration and monitoring of servers, VMs, Docker/Podman Containers, and laptops as well as for the management of users. Those tools must scale up to some ten thousands laptops/users. The EU OS project proposes to rely on FreeIPA for identity management and Foreman for Linux laptop fleet management.
Third-Party Support
The public sector wants that their existing possibly proprietary or legacy third-party hardware2 or appliances (think SAP) remain supported. This one is tricky, because it is each third party that decides what they support. Of course, any third-party vendor lock-in should be avoided eventually, but this takes time and some vendor lock-ins are less problematic than others.
Supply Chain Security and Consistency
The public sector must secure its supply chains. This becomes generally easier with less chains to secure. A Linux desktop based on Fedora and KDE requires about 1200 Source RPM packages3. A Linux server based on Fedora requires about 300 Source RPM packages. The flatpak runtime org.fedoraproject.KDE6Platform/x86_64/f43 requires about 100 Source RPM packages. I assume the numbers for Ubuntu/Debian/openSUSE are similar. So instead of securing all supply chains independently (possibly through outsourcing), the public sector can choose one, secure this one, and cover several use cases with the same packages at no or significant less extra effort. Also updates, testing, and certifications of those packages would benefit then all use cases.
Accreditation and Certifications
Some public sector organisations require a high level of compliance with cyber security, data protection, accessibility, records keeping, interoperability, etc. The more often a (similar) Linux distribution has passed such tests, the easier it should get.
Forward-looking Sovereignty and Sustainability
The public sector wants to work with stable vendors in stable jurisdictions that minimise the likelihood to interfere with the execution of its public mandate4. Companies can change ownership and jurisdiction. While not a bullet-proof solution, a multi-stakeholder non-profit organisation can offer more stability and alignment with public sector mandates. Such an organisation must then receive the resources to execute its mandate continuously over several years or decades. With several independent stakeholders, public tenders become more competitive and as such more meaningful (compare with procurement of Microsoft Windows 11).
Geographical Dimension
I have the impression that some governments would like to choose a Linux distribution that (a) local IT companies can support and (b) creates jobs in their country or region. In my view the only chance to offer such advantage while maintaining synergies across borders is to find a Linux distribution supported by IT companies active in many countries and regions.
While the project EU OS has EU in its name, I would be in favour to not stop at EU borders when looking for partners and synergies. It has already inspired MxOS in Mexico. Then, think of international organisations like OSCE, Council of Europe, OECD, CERN, UN (WHO, UNICEF, WFP, ICJ), ICC, Red Cross, Doctors Without Borders (MSF), etc. Also think of NATO. Those organisations are active in the EU, in Europe and in most other countries of the world. So if EU OS can rely on and stimulate investments in a Linux distribution that is truly an international project, international organisations would benefit likewise while upholding their mandated neutrality.
Diversity of Linux Distributions for EU OS
Douglas DeMaio (working for SUSE doing openSUSE community management) argues in his blog post from March 2025: Freedom Does Not Come From One Vendor. The motto of the European Union is ‘United in Diversity’. Diversity and decentralisation make systems more robust. However, when I see the small scale of on-going pilots, I find that as of December 2025, it is better to unify projects and choose one single Linux distribution to start with and progress quickly. EU OS proposes to achieve immutability with bootable containers (bootc). This is a cross-distribution technology under the umbrella of the Cloud Native Computing Foundation that makes switching Linux distributions later easier. Other Linux distributions could meanwhile implement bootc, FreeIPA, as well as Foreman support, and setup/grow their multi-stakeholder non-profit organisation, possibly with support of public funds they applied for.
The extend to which more Linux distributions in the public sector provide indeed more security requires an in-depth study. For example, consider the xz backdoor from 2024 (CVE-2024-3094).
Early adopters would have caught the vulnerability independently of the Linux distribution (except ArchLinux 👏). Larger distributions can possibly afford more testing. Older distributions with older build systems are more likely to offer tarball support (essential for the xz backdoor) as back then git was not yet around. To avert such supply chain attacks, implementing supply-chain hardening (e.g. SLSA Level 3) consistently is certainly important and diversification of distributions or supply chains makes it harder first.
Comparison of Linux Distributions
In the comparison here, I focus on Debian/Ubuntu, Fedora/RHEL/AlmaLinux and openSUSE/SUSE, because they are beyond doubt battle tested with many users in corporate environments already. They are also commonly supported by third parties. Note that I don’t list criteria for which all distributions perform equally.
I find it extremely difficult to find reliable public numbers on employees, revenues and donations. I list here what I was able to find in the Internet, because I think it helps to quantify the popularity of the enterprise Linux distribution in corporate settings. Numbers for Debian are not very expressive due to the many companies othen than Ubuntu involved. Let me know if you find better numbers.
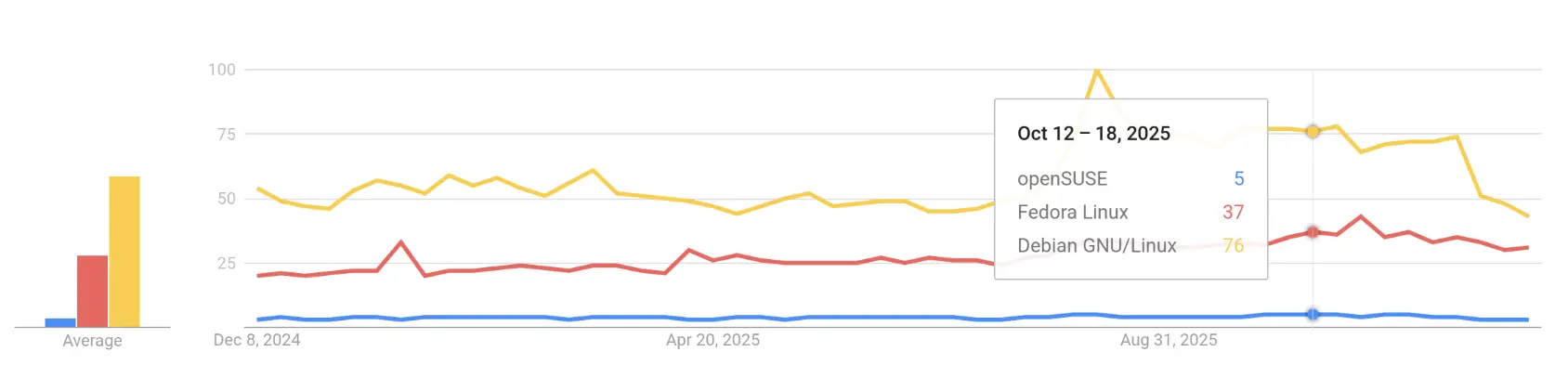
Other than company figures, also the number of search queries (Google Trends) given an impression on the popularity of Linux distributions. Find here below the graph for the community Linux distributions as of December 2025.
Google Trends for Debian, Fedora and openSUSE worldwide 2025 (Source)
Conclusions as of December 2025
Obviously, it is challenging to propose comprehensive criteria and relevant metrics to compare Linux distributions for corporate environments for their suitability as base distribution for a project like EU OS. This blog post does not replace a more thorough study. It offers however some interesting insights to inform possible next steps.
Debian is a multi-stakeholder non-profit organisation with legal entities in several jurisdictions. Unfortunately, its bootc support is in an early stage only and it lacks support for some third-party software vendors such as SAP. For corporate environments, Debian does not offer alternatives to FreeIPA and Foreman, which work best for Fedora/RHEL/AlmaLinux, but also support Debian.
Fedora is in this comparison the 2nd largest community in terms of mirrors and Github repositories. Fedora has no legal entity independent from its main sponsor RHEL. However, AlmaLinux is a multi-stakeholder non-profit organisation, albeit very US-centered. With RHEL front running Linux in enterprise deployments for several years, most use cases are covered, including building Flatpak apps from Fedora sources. Fedora downstream distributions with bootc (ublue, Bazzite, Kinoite) run already on tens of thousands systems including in the EU public sector.
openSUSE has most success in German-speaking countries and the US (possibly driven by SAP). Internationally, it is significantly less popular. openSUSE has no legal entity independent from its main sponsor SUSE registered in Luxembourg and headquartered in Germany. For corporate environments, openSUSE does not offer alternatives to FreeIPA and Foreman, which support openSUSE only as clients. While Uyuni6 offers infrastructure/configuration management, it remains unclear if it can replace Foreman for managing fleets of laptops. openSUSE’s bootc support is in an early stage only.
No Linux distribution fulfills all the criteria. Independently of the distribution, corporate environments would rely on FreeIPA, Foreman, Keycloak, podman, systemd, etc. that Red Hat sponsors. Debian is promising, but its work to support bootc is not receiving much attention. AlmaLinux is promising, but would need to proof its independence from politics yet as it is a fairly new project (1st release in 2021) and doubts remain on its capacity to support Fedora (as Red Hat does) in the long run. Microsoft blogged this week about their increasing contributions to Fedora. Maybe European and non-European companies can step up likewise in 2026, so that Fedora can become a multi-stakeholder non-profit organisation similar to AlmaLinux today.
Community Talk at Fosdem
My 30 min talk on this topic has been accepted at the community conference fosdem 2026 in Brussels, Belgium! Please consider to join if you are at fosdem and let me know your thoughts and questions. The organisers have not yet allocated timeslots yet, but I believe it will take place on Saturday, 31st January 2026.
Talk title
EU OS: learnings from 1 year advocating for a common Desktop Linux for the public sector
Track title
Building Europe’s Public Digital Infrastructure
All the best,
Robert
I know that the public sector relies on vendors that ship embedded Linux on WiFi routers, traffic lights, fleet of cars, etc. If anyway you identified a relevant use case that is missing here, please feel free to let me know and I will consider to add it here. ↩︎
I counted Source RPM packages with rpm -qa --qf '%{SOURCERPM}\n' | sort -u | wc -l in each given environment. ↩︎
The public sector also wants to avoid vendor lock-in, which is just one specific form to ‘interfere with the execution of its public mandate’. ↩︎
FreeIPA does not run on openSUSE, but supports openSUSE clients. Alternative software for openSUSE may be available. Community members suggestKanidm, but is lacks features and development seems stalled. ↩︎
Foreman runs only on Debian/Fedora/RHEL/AlmaLinux, but supports openSUSE clients. SUSE offers Rancher, which is limited to Kubernetes clusters. Uyuni and its enterprise-supported downstream SUSE Multi-Linux Manager offers configuration and infrastructure management based on SALT. ↩︎↩︎2
In this post, I share my personal perspective on distroless containers for corporate use, hence with a view on compliance. I offer an alternative to Nix Flakes using Fedora and Podman.
For several years, Bitnami offered many standard cloud component Container images and Kubernetes Helm charts, e.g. for PostgreSQL, MariaDB, Redis, or MongoDB. I think they were well maintained, used in many production setups, and used with Bitnami subscriptions by paying customers. Also governments used them (e.g. the German government with openDesk and BundesMessenger or the European Commission with SIMPL-Open). In 2019, Bitnami was bought by VM Ware.
In 2025, Bitnami revaluated their business case and decided to discontinue their current offering:
In a time, where many customers find their dependency with VM Ware already problematic, customers are sceptical towards a mere upgrade to the new Bitnami offering. So it comes to no surprise, that the Internet is full of discussions on alternatives. Before I present three of them, let me recall the challenges:
supply chain security
complexity due to diverging supply chain sources
transparency
compliance with NIS2 (Network and Information Security (NIS) Directive 2, adopted in November 2022 and in principle effective from 2025), example measures from nis2compliant.org:
robust vulnerability handling and disclosure practices
Secure supply chain interactions and mitigate risks related to suppliers or service providers, ensuring comprehensive security from end to end
incident detection, triage, and response to meet reporting obligations
supply chain security, including security-related aspects concerning the relationships between each Union entity and its direct suppliers or service providers
establishment of software supply chain security through criteria for secure software development and evaluation
any other applicable national legislation
So what are the options to manage supply chain security with a view of reaching compliance? I believe it is impossible for an individual organisation to take care of the supply chain security directly for all their software in use. On top, any attempt would not be good use of (public) money. Hence, the goal must be to outsource and to seek synergies with organisations having similar or higher requirements.
Some German products may switch from Bitnami to CloudPirates.io. CloudPirates is a company like Bitnami, but it is in Germany and hasn’t been bought by VM Ware (yet). Read their German blog post addressing the Bitnami policy change. I have checked their MariaDB helm chart. It relies on the community MariaDB container.
To ensure compliance when using their work, it may be necessary to introduce obligations for CloudPirates, which they may allow only against a fee.
In alternative would be RedHat Linux, that also offers all kinds of containers with maintenance against a fee.
Governments could build containers for their own ministries. This is what parts of the German government currently explore. But then, there are many ways how this can be organised.
Upstream: The Government could just review the community images that everyone is using. However, the community may not be reactive enough or have diverging standards, etc.
Downstream: The Government could maintain their own downstream fork and still collaborate with the community.
In both situations, you have to decide with which community. Consider for instance MariaDB. Relevant communities are:
the MariaDB community
the Debian community that packages (and patches) MariaDB
the Opensuse community that packages (and patches) MariaDB
the NixOS community that packages (and patches) MariaDB
the Fedora/CentOS Stream/AlmaLinux community that packages (and patches MariaDB)
The US Government got a project on this at https://repo1.dso.mil/dsop, but it consists of many repos, so that I cannot grasp easily their general apporach. Their NodeJS (slim) image relies on Alpine sourced from their own mirror.
The German Government decided to test NixOS Flakes to build containers from Debian packages that contain the bare minimum of software. If the container does not even contain a package management system, then it is called distroless. Read more about it from Google, Docker, RedHat, or Bitnami (minideb).
The following list of their requirements is copied over from the (nodejs image README.md):
Base Image Security
Minimal base images are used - There is no base image at all, since this build is done using nix and debian packages directly.
Base image provenance is verified - There is no base image at all, since this build is done using nix and debian packages directly.
Immutable artifact references are used - There is no base image at all, since this build is done using nix and debian packages directly.
Base Image can be automatically updates (or after a fixed period of time to avoid being a victim of a supply chain attack) - There is no base image at all, since this build is done using nix and debian packages directly.
Build Process Security
Reproducible builds are implemented - Nix is being used to ensure that builds are reproducible, meaning the same source code and build instructions always produce identical container images.
Build environment is isolated - Build runs in a Kubernetes GitLab-Runner. Nix is instructed to not do any sandboxing. However, the build environment is isolated from the host system and other builds to prevent contamination.
Build provenance is attested - Build process generates cryptographically signed provenance (metadata about who, what, when, and how the artifact was built), ideally at SLSA Level 2 or higher. This creates an auditable trail proving the container came from your legitimate build system and hasn’t been substituted.
Containers are signed - Images are signed using Cosign to ensure authenticity and integrity. They can be verified using the cosign.pub public key.
Dev / Compile time dependencies are removed - Uses Nix
Component Management & Transparency
All components are identified - Have a look at the config json files in the root directory. All components, including their versions, urls and checksums are listed there as input to the build process.
Component PURLs can be matched to CVE reports We are using debian packages to match against known CVEs. Besides that, we are downloading Nodejs 24 from nodejs.org. To match that against CVEs, we are using the PURL constructed from their GitHub repository: pkg:github/nodejs/node@<version>. We can match this using DevGuard against CVEs (https://osv.dev/list?q=github.com%2Fnodejs%2Fnode).
Component checksums are verified - All checksums are either in config.json or in flake.nix.
Regular updates are provided for all components or latest Builds like new nodejs versions - Components receive timely updates and patches from upstream maintainers, and your build process incorporates these updates regularly. This ensures your container stays protected against newly discovered vulnerabilities in its components.
Components can be automatically updated in a timely manner (or after a fixed period of time to avoid being a victim of a supply chain attack) - An automated pipeline exists to detect, test, and deploy component updates without manual intervention. Can provenance or signatures be verified for upstream components? This ensures security patches are applied quickly, reducing the window of exposure to known vulnerabilities.
Secrets & Sensitive Data
No secrets in images - Credentials, API keys, certificates, and other sensitive data are never embedded in container images; they are injected at runtime via secrets management systems. This prevents secrets from being exposed in image layers, which can be extracted by anyone with access to the image.
Runtime Configuration
Resource limits are documented - Since this is an runtime image only, resource limits heavily depend on the application being run.
Container runs as non-root user - User 53111 (nonroot) is used as non-root user.
Compliance & Vulnerability Management
SBOM is attested - A Software Bill of Materials (SBOM) is generated, accurate, and cryptographically attested to prove the container’s contents. This provides a tamper-proof inventory of components for compliance, license management, security scanning, and incident response.
Vulnerability management is done in a timely manner - We are using DevGuard to monitor vulnerabilities in our components. New vulnerabilities are assessed and remediated promptly based on their severity and exploitability.
VEX is attested - Vulnerability Exploitability eXchange (VEX) documents are provided and attested, indicating which vulnerabilities are exploitable in the specific container context and which are mitigated. This reduces alert fatigue by documenting which CVEs don’t actually affect your container due to configuration or usage patterns.
Fedora-based distroless Container images
As part of my pet pilot project EU OS, I rely on compiled code (i.e. RPM packages) from Fedora. Fedora (and their downstream stable versions Redhat RHEL, CentOS Stream, AlmaLinux) have technologies in place to cover most if not all Government use cases for open source:
operating system for the corporate laptop of the end user (check out EU OS for some inspiration)
operating system for cloud servers, including Kubernetes clusters
container images for cloud workloads
So if we reuse the compiled code for all purposes, then the supply chain security becomes more managable (but due to such centralisation, vulnerabilities could have a higher impact).
Let us check, how distroless container images can be built from Fedora RPM packages. Fedora described this in a blog post from 2021. Meanwhile, things have changed a little bit and such Fedora distroless images can also be composed with podman and its multi stage builds. That’s my example for a small NodeJS container:
# kate: hl Containerfile;ARG ROOTFS="/mnt/rootfs"ARG HOME=/home/nonrootARG DNF="dnf"ARG RELEASEVER="42"FROMquay.io/fedora/fedora-minimal:42asbase# alternatively:# ARG RELEASEVER="9"# FROM registry.access.redhat.com/ubi9/ubi-minimal as base# or# ARG RELEASEVER="10"# FROM quay.io/almalinuxorg/10-minimal:10.0 as baseARG ROOTFSARG DNFARG RELEASEVERARG DNF_OPTS="--installroot=${ROOTFS} --releasever=${RELEASEVER} --noplugins --config=/etc/dnf/dnf.conf --setopt=install_weak_deps=0 --setopt=cachedir=/var/cache/$DNF --setopt=keepcache=1 --setopt=reposdir=/etc/yum.repos.d --setopt=varsdir=/etc/dnf"USER root# pinning of software versions possible with https://dnf5.readthedocs.io/en/latest/dnf5_plugins/manifest.8.html# (see also: https://github.com/rpm-software-management/dnf5/pull/2425)RUN --mount=type=cache,target=/var/cache/$DNF\
mkdir-p${ROOTFS}&&\
$DNF${DNF_OPTS}-y--nodocsinstall nodejs22
FROM scratchARG ROOTFSARG HOMECOPY --from=base ${ROOTFS} /RUN \
mkdir-p$HOME&&\
printf"nonroot:x:1001:\n">> /etc/group &&\
printf"nonroot:x:1001:1001:Nonroot User:/home/nonroot:/sbin/nologin\n">> /etc/passwd &&\
printf"nonroot:!:20386::::::\n">> /etc/shadow &&\
chown-R 1001:1001 $HOME&&\
chmod-Rg=u $HOMEUSER 1001WORKDIR $HOMEENTRYPOINT ["/bin/bash"]
How does it compare? What is missing?
The container image is not yet reproducible in the sense that it always uses the latest packages at the time of the build. However, with RPM manifests, the Fedora package manager can be instructed to install specific software versions, similar to npm and its package.json files. I could not enable it yet, because the feature is currently disabled, as the library is not yet widely available in the Fedora package repositories.
SBOMs can be generated directly from the RPM database. Trivy can list vulnerabilities for a given SBOM, but only for distributions with support (fedora is not; CentOS Stream, RHEL, and AlmaLinux is). Trivy can also generate SBOMs for the container images directly. Renovate can be configured to update RPM manifest files.
The container image also supports a non-root account.
The container currently contains still bash, find, sed, grep as those tools are pulled in as a dependency of ca-certificates. The latter is required by nodejs. To remove them, an alternative custom ca-certificates package needs to be prepared that has no such dependencies. Interestingly the image is nevertheless smaller. See also: https://discussion.fedoraproject.org/t/169906/2
REPOSITORY
TAG
MAGE ID
CREATED
SIZE
localhost/fedora-micro-nodejs
latest
df43085da156
47 seconds ago
134 MB
registry.opencode.de/open-code/oci/nodejs
22
db0046e37ec6
55 years ago
157 MB
quay.io/hummingbird/nodejs (Fedora-based)
latest
e05bec4f638e
259 MB
I think the main advantage would be to avoid Nix flakes. Maybe Nix flakes are cool, but the system is apparently still experimental/beta software (see here or here). Also, many developers have not worked yet with Nix flakes. So this is something new to learn. Using Nix flakes doesn’t make podman or Containerfiles redundant. So learning Nix flakes does not replace learning Podman or Containerfiles.
Obviously, this advantage would apply equally to building Podman distroless containers with OpenSUSE RPMs or Debian DEBs. All it takes is a build tool that can install dependencies in a separate folder. For dnf, this is done with the option --installroot. If an organisation has already solved supply chain security for a repository of compiled code, then I believe it is good practice to reuse this repository.
Belgium provides the Belgian eID software also for Fedora, but on Atomic Fedora, the setup is a bit different. Let’s test eID authentication and PDF signing
To do my tax declaration in Belgium, I have several login methods. One of them is the Belgian eID (eidas). To use it, you need an ID card (or resident card) and a smart card reader.
I use the smart card reader CardMan 3121 from OMNIKEY. The setup will also allow you to sign PDF documents and emails with your Belgian ID card. Neat! Other countries would require the purchase of additional certificates, but in Belgium you should have it already – free of charge.
Note that on Atomic Fedora desktops, Firefox is (as of May 2025) installed as system application and other browsers (such as Chromium) is installed in a flatpak sandbox. So it is very likely that other browsers than Firefox cannot access the eID setup on the system.
https://rpmfusion.org/Howto/OSTree on the setup of third-party RPM repositories for rpm-ostree based distros (such as Fedora Kinoite/Silverblue)
First Test with eid-viewer
You should find now in your application menu eID Viewer. Or you lunch in the terminal eid-viewer. Enter your card. Then you should see the data on your card already.
This is not so clear yet. Okular is usually a flatpak. In order to have gpg find the card reader, I had to restart a service first:
gpg --card-status# => can't connect to 'socket:///home/rriemann/.gnupg/log-socket': No such file or directory
systemctl restart pcscd
gpg --card-status# can't connect to 'socket:///home/rriemann/.gnupg/log-socket': No such file or directory# Reader ...........: OMNIKEY AG CardMan 3121 00 00# Application ID ...: 534C4090413423078AA5B22712924134# Application type .: PKCS#15
Okular supports as PDF signature backends both NSS and GnuPG (S/MIME). As it does not work with any option, I check in the app Kleopatra (KDE certificate manager) the smartcards. It turns out I have to configure the trust of various certificates belonging to the Belgian authorities.
Then, I restart Okular again and choose under Settings → Configure Backends… → PDF backend configuration the option Signature Backend to GnuPG (S/MIME). I get the following feedback:
When I then choose in the Okular Tools menu the signing option, I end up in a loop with a pinentry-qt dialogue:
Please insert the card with serial number:
[redacted serial number]
It does not work. So close!
An alternative for signing offers the command line tool pdfsig.
With pdfsig -backend GPG -list-nicks, I get a list of fingerprints. One of the hardware ones is for signing, one for authentication. The smartcard tab in the app Kleopatra also displays the names/purposes alongside the fingerprint. So it may be better suited. Otherwise, try out all to find the one for signing. Then, PDFs should be signed with:
pdfsig unsigned.pdf signed.pdf -add-signature-nick[redacted my fingerprint] -reason'for fun!'
Unfortunately, I only get an error:
signDocument: error getting signature info
We can try briefly the NSS backend with pdfsig. For this, use pdfsig -list-nicks to check nick names:
Then, I get queried for the pin and upon entry, the PDF is signed. This can be checked as follows:
# pdfsig signed.pdf
Digital Signature Info of: signed.pdf
Signature #1:
- Signature Field Name: 34B8E9A9E274A3BCE18E633ABD5B1ECA
- Signer Certificate Common Name: Robert Riemann (Signature)
- Signer full Distinguished Name: CN=Robert Riemann (Signature),serialNumber=[redacted],givenName=Robert,SN=Riemann,C=DE
- Signing Time: May 29 2025 14:58:22
- Signing Hash Algorithm: SHA-256
- Signature Type: adbe.pkcs7.detached
- Signed Ranges: [0 - 515528], [535530 - 536032]
- Total document signed
- Signature Validation: Signature is Valid.
- Certificate Validation: Certificate issuer isn't Trusted.
It remains yet to determine why the certificate validation fails even though the certificate is marked trusted in Kleopatra. Let me know if you have an answer!
The Spanish techblog ‘MuyLinux’ has interviewed Robert Riemann on EU OS. Find here the English version of the interview.
The interview has been conducted by Jose Pomeyrol and published originally in Spanish on MuyLinux. Find the English version here below.
The other day I noticed something curious: after updating one of the
apps I use regularly, it now shows a bold message when starting up —
“Made with ❤️ Europe.” It’s similar to the tagline on the credits page
of EU OS, a new Linux distribution being discussed in various
tech-focused forums these last days. What do these two projects have in
common? Among other things, they are both developed in Europe — or at
least, their final form is.
Europe, and the European Union in particular, is preparing to face
challenges unprecedented in recent history: tensions with Russia and
calls for rearmament among Eurozone members; Trump’s return to the White
House and a new wave of protectionist policies; and China’s
technological rise, especially in AI. Europe must respond on multiple
fronts — and the complexity of these issues doesn’t make things any
easier.
To explore all this, we exchanged via email with Robert Riemann,
master in physics and PhD in computer science, Head of Digital
Transformation in the Technology and Privacy Unit of one body of the EU,
and project lead of EU OS, a Linux distribution with
institutional ambitions… proudly “Made with ❤️ in Brussels.”



 The other day I noticed something curious: after updating one of the
apps I use regularly, it now shows a bold message when starting up —
“Made with ❤️ Europe.” It’s similar to the tagline on the credits page
of
The other day I noticed something curious: after updating one of the
apps I use regularly, it now shows a bold message when starting up —
“Made with ❤️ Europe.” It’s similar to the tagline on the credits page
of